Each character of the string would be shifted one letter down the alphabet, A > B if the shift value is 1, and so on.
I’ve seen some posts about this before, but this is for a ARG, not encrypting player messages or whatever, and the earlier solutions I’ve seen translate some letters into symbols like ‘>’ because of how internalNC works.
It’s fine if the script would entirely ignore numbers and symbols, and there’s no need for it to be decryptable by the script, the player would go through that trouble themselves. Obviously the Caesar cipher is much tougher to break if it uses a different alphabet, and the only factor that I want the player to struggle with is the shift value through only the alphabet’s characters.
Create a table with all the letters of the alphabet. Examine each letter by using a for loop. Find the index with table.find. If it is a letter then the index should be real. return index + 1 for the new letter. If the letter is Z, then make it A.
This may be complicated, but I don’t know any simpler way as of now.
Oh boy, this is precisely what I wanted to avoid, but I guess that’s it.
I forgot to mention that I’m crap at scripting - What would the function’s loop look like? No need to paste the table, just the necessary vocabulary.
This may be a little overcomplicated, but hope this helps!
local alphabet = {"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"}
local letters = #alphabet
local function ceasercipher(original: string, amount: number, usecapitals: boolean) -- Depends, may reduce time if you don't
-- Checking
assert(typeof(original) == "string", "Expected string got "..typeof(original))
assert(typeof(amount) == "number" and amount == amount//1 and math.abs(amount) <= letters, "Expected integer, got "..tostring(amount)) -- making sure it's an integer
local finished = ""
for i = 1, string.len(original) do
local letter = string.sub(original, i, i) -- get the letter
local index = table.find(alphabet, string.lower(letter)) -- lower it for getting the index
local finishedletter = letter -- what we're editing
if index then
local newindex = index + amount -- the new letter index
local newletter = alphabet[newindex] -- applied
if not newletter then
newletter = alphabet[index - (letters - amount)] -- if it goes over, then bring it back
end
if usecapitals then -- if it's capital, then keep it capital
newletter = letter == string.upper(letter) and string.upper(newletter) or newletter
end
finishedletter = newletter
end
finished = finished..finishedletter
end
return finished
end
print(ceasercipher("Yo wassup bruh", 1, true))
print(ceasercipher("Zp xbttvq csvi", -1, true))
print(ceasercipher("Zp xbttvq csvi", -1, false))
--[[ Output:
Zp xbttvq csvi
Yo wassup bruh
yo wassup bruh
]]
(My bad, don’t really know how to spell caesar!)
Thank you so much! This is great!
1 Like
Hope it doesn’t take to much of a toll on the performance!
1 Like
i mean you could also instead store each string as a sequence of indices, then do the math on the sequence of indices and then map that to the alphabet. (basically something like C characters)
Assuming we use the alphabet table you defined, you could say store “hello” as the sequence {8,6,12,12,15} and then add to that (say shift everything down by 2) to get {10,8,14,14,17} and then go back to the alphabet table and then construct the string from there to get “ihnnq”
also i think you can just have the adjusted index as
index_adjusted = 1 + ((old_index + offset) modulo length_of_array)
basically youre taking the remainder of the sum and the length of the array, so it will always be less than the length of array. offset by one bc lua has 1-based indexing and modulo does output 0 if the left hand side of the modulo is perfectly divisible by the right hand side.
i think this might cost more memory to store the strings, but would be less costly than searching the entire array through table.find() in terms of time complexity. this is because for each character in the length of the string its only 1 operation (look up the number) but table.find() for each character searches the entire array at worst. Alternatively, you could use a map between the letters and the indexes, so you have one table where its characters → integers, and the original alphabet table maps from integers → characters. This might be a bit more efficient in terms of memory and might be faster depending on how you construct the integer sequence. Thought of the integer seqeunce bc for some languages (C, C++, and Python) you can treat characters as numbers and add and subtract from them to get different characters.
1 Like
local character_to_integer = {['a'] = 1,['b'] = 2,['c'] = 3,['d'] = 4,['e'] = 5,['f'] = 6, ['g'] = 7,['h'] = 8,['i'] = 9,['j'] = 10, ['k'] = 11, ['l'] = 12, ['m'] = 13, ['n'] = 14, ['o'] = 15, ['p'] = 16, ['q'] = 17, ['r'] = 18, ['s'] = 19, ['t'] = 20, ['u'] = 21, ['v'] = 22, ['w'] = 23, ['x'] = 24, ['y'] = 25, ['z'] = 26,}
local integer_to_character = {"a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"}
function caeser_alt(s : string, offset : number)
assert(typeof(s) == "string", "asdnasdsad")
assert(typeof(offset) == "number" and offset == offset//1)
local finished = ""
for i = 1, string.len(s) do
local letter = string.sub(s, i, i) -- get the letter
if letter == " " then
finished = finished .. letter
continue
end
finished = finished.. integer_to_character[1+(character_to_integer[letter]+offset) % #integer_to_character]
end
return finished
end
code for my second solution (use two tables)
some speed performance (top time is userunmanned’s code, although modified slightly with a modulo to handle offsets >[alphabet length], bottom time is mine)
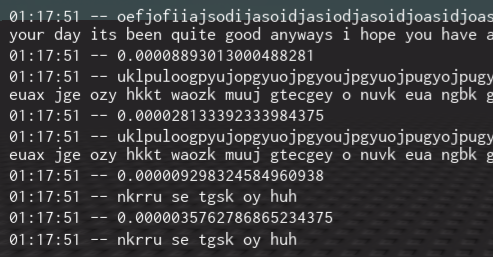
Note, my code does not handle capitals. Test was done with capital handling turned off. This can be integrated by just having capitals in the dictionary, although this may result in a capital being mapped to a non-captial (however, as both algorithms are reversable, it should not matter)
1 Like
I was bored and wanted to try this myself as I like to write overly optimized things, so here’s a function to handle capitals and ignore any characters that are not a-z or A-Z. I also notice caeser_alt had an offset that was going one step too much.
local bwu8,o1,o2,m = buffer.writeu8,65,97,26
local function caesar_opt(input: string, offset: number)
assert(typeof(input)=="string", "Input value is not a string")
offset//=1
local of1,of2 = o1-offset,o2-offset
local len = #input
local buf = buffer.create(len)
for i = 1, len do
local c = string.sub(input,i,i)
local b = string.byte(c)
if b > 96 and b < 123 then
bwu8(buf,i-1,(b-of2)%m+o2)
continue
elseif b > 64 and b < 91 then
bwu8(buf,i-1,(b-of1)%m+o1)
continue
end
bwu8(buf,i-1,b)
end
return buffer.tostring(buf)
end
Seems to run about 15% faster, tested with 200000 loop calls on the string “the quick brown fox jumps over the lazy dog”
(yes I used a buffer for the string building because it seemed to run faster???)
EDIT: Removed unnecessary constants
2 Likes
Woah! I’ll check out these two if the first solution ever really shows performance issues. Thanks, guys!
1 Like
This topic was automatically closed 14 days after the last reply. New replies are no longer allowed.